CLIP论文详解,来看看这篇论文有什么创新点
今天来讲讲经典的一个多模态论文CLIP
今天来讲讲经典的一个多模态论文CLIP,要说起来这个东西也是openai发的,那时候的openai可以说是真open。今天来讲讲这篇论文给我们带来一些什么样的视角和启发。
从它的架构开始,CLIP其实就是个双编码器(dual‑encoder)架构,一条路干图像,一条路干文本,然后把这两个给映射到同一个向量空间里面。
图像方面CLIP用的是Resnet和ViT两种编码器,文本编码方面用的就是标准的 transformer,用来把文本转成embedding。
按照他们论文和代码里提到的,预训练阶段用的是对比学习训练了一个图像编码器和一个文本编码器,也就是说图文通过两个模态的编码器编码之后,做一个对比学习的任务,尽量把那些能正确匹配上的图文对的向量在向量空间上拉的更进一些,而把不是原本的图文对的,在向量空间上拉得更远些,尽量去把图像编码器和文本编码器的输出在空间上拉近。
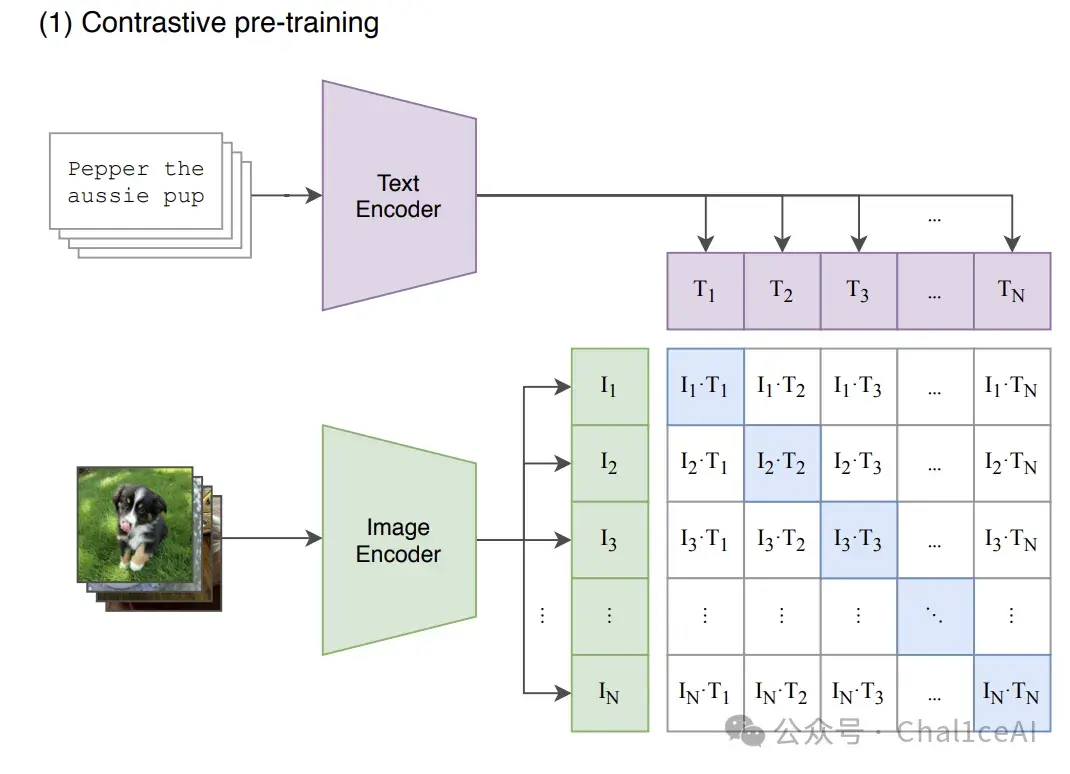
刚才也说了后面模态融合训练用的是简单的对比学习,就是那种简单的点积计算,不过这种方法只适合检索方面的的任务,在细粒度匹配和逻辑推理任务上面表现肯定是不行的。
点积比较的是图像embedding和文本embedding,它其实看不到文本和图片区域之间的关系,比如说文本是A man riding a horse,但是图片是一个人站在马的旁边,没有骑上去,CLIP很可能会判断这张图和这个描述挺像的,因为“man”和“horse”都出现了,语义空间距离也很近,但实际上语义错了,人没骑上马。这种细节判断点积是无能为力的,只有那种融合编码器(cross-attention-based)的模型,比如UNITER、ViLT、BLIP,才能把“riding”这个动词和“人在马上”这种视觉细节做深度交互对齐,而且像这种在VQA这些任务上表现也会一般般。
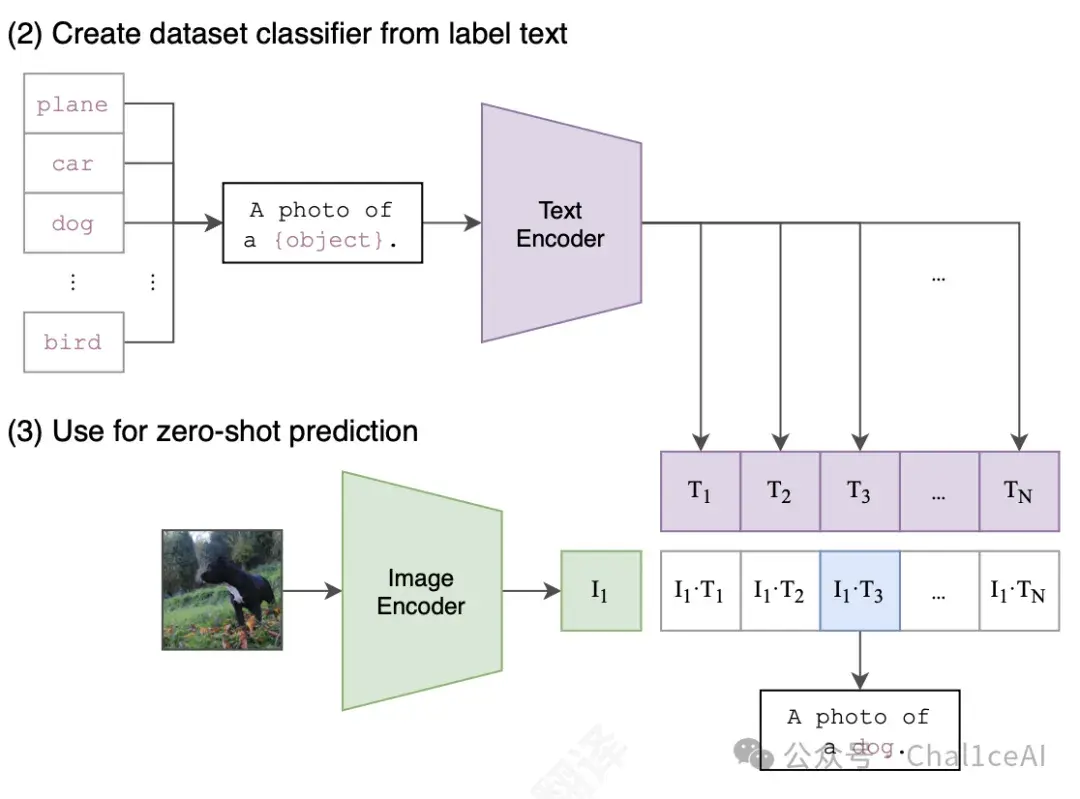
有了预训练完的两个编码器之后,他们进行了一些测试工作,把CLIP转变为零样本分类器,把数据集里面的所有类的名称作为文本配对集,然后预测跟给定图像最佳配对的标题的类别,这点就是论文里的零样本迁移。
CLIP的贡献其实可以总结成一句话:它用极其简单的方式,把图像和语言统一到了一个通用的语义空间里,而且用“真实世界”的数据大规模预训练,让图文系统第一次具备了“类人类”的直觉匹配能力。
CLIP最大的贡献还是用对比学习 + 网络抓来的图文对,提出这种通用但效率极高的双编码器 + 点积的架构,搞出通用模态对齐模型,在CLIP出现之前,图文多模态模型基本都是靠人工标注数据学出来的,比如COCO caption、Visual Genome、VQA等等这些任务,一两百万对数据都算大的了,而且任务很“重”,你要做caption就得用decoder,做问答得加额外模块,这就导致这些模型很难泛化,你换个任务,模型得重设计。
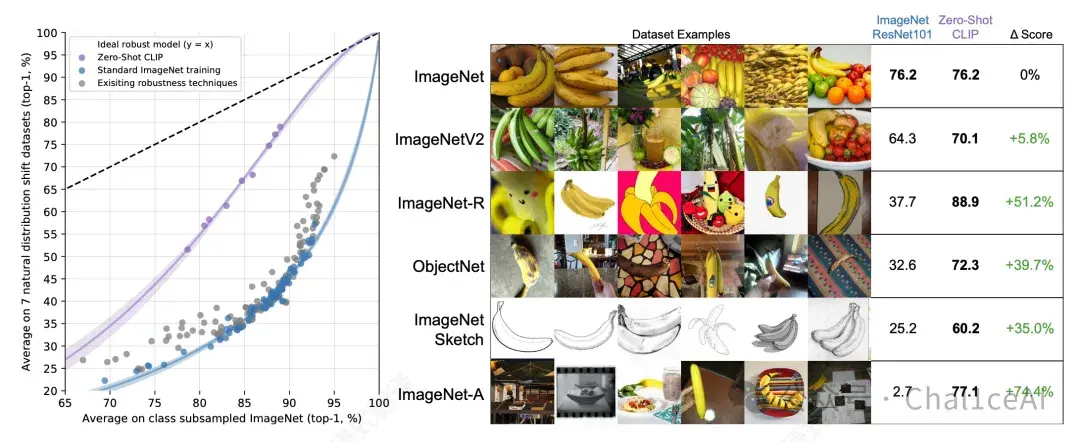
而且CLIP开启了零样本视觉识别的新时代,从论文的对比可以看出,它在分类任务上比起resnet的水平要高上不少,在完全没有看过ImageNe 数据的情况下,凭一堆提示词就能达到跟ResNet类似的准确率,把分类任务变成了自然语言提示匹配任务,极大地提升了模型的泛化能力。
数据集方面CLIP用的是从网上拿下来的大规模图文数据集,主要有三个MS-COCO (Lin et al., 2014), Visual Genome (Krishna et al., 2017), and YFCC100M (Thomee et al., 2016),然后经过过滤,只保留具有自标题或英文描述的图像,数据集规模缩小了6倍,仅剩1500万张图片,和imagenet的规模差不多。
其他的实验细节还有训练所用的优化器这些大家可以去论文里面扒,里面那些对于我而言感觉没必要讲,是一些比较稀疏平常的东西。
参考资料:
https://openai.com/index/clip/