VLMo论文详解,来看看这篇论文有什么创新点
今天带来的这篇是VLMo,也算是一篇近几年比较经典有代表性的论文了,把moe的思想带入到了多模态领域,希望这篇论文能够带给你新的视角。
今天带来的这篇是VLMo,也算是一篇近几年比较经典有代表性的论文了,把moe的思想带入到了多模态领域,希望这篇论文能够带给你新的视角。
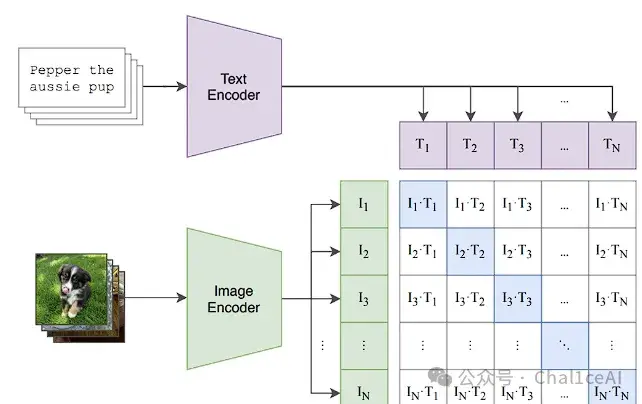
我们先说说以前的干法:要做图文任务,最常见的两条路。一条是把图片和文本分开编码,然后靠最后的向量做“相似度”匹配,比如CLIP、ALIGN这类双编码器;
另一条是把图像特征和文本特征拼在一起,用带跨模态注意力的transformer 做深度融合,典型的像UNITER、ViLT这些融合编码器。
双编码器跑检索速度快,归根到底算个向量点积,时间复杂度线性;融合编码器效果好,尤其是视觉问答和视觉推理,但要穷举图片-文本对再一起跑,时间复杂度平方,尤其一开始还得跑目标检测器或卷积提取区域特征,整个pipeline慢得飞起,这些在上一篇ViLT的论文解读里面由提到过,相关的阅读:
VLMo 的初心就是:“我既想要双编码器检索快,又想要融合编码器效果好,为什么不能统一到一个模型里?”
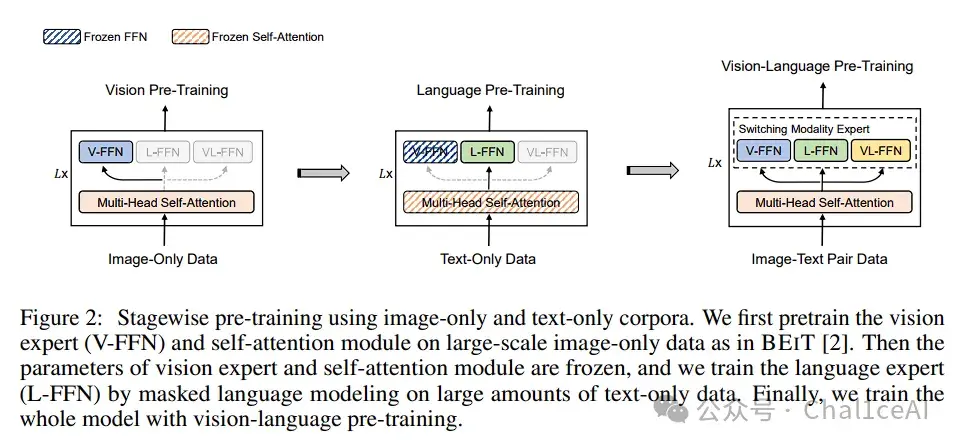
它提出了Mixture‑of‑Modality‑Experts(MoME)Transformer,核心思路在每个Transformer block里不只一个feed‑forward层,而是一坨专家,各有各的任务,专门负责Vision、Language、或者Vision‑Language融合,在模型调用的时候就会根据任务来激活专家,比如vqa之类的任务就会激活vl-ffn这一块的专家。
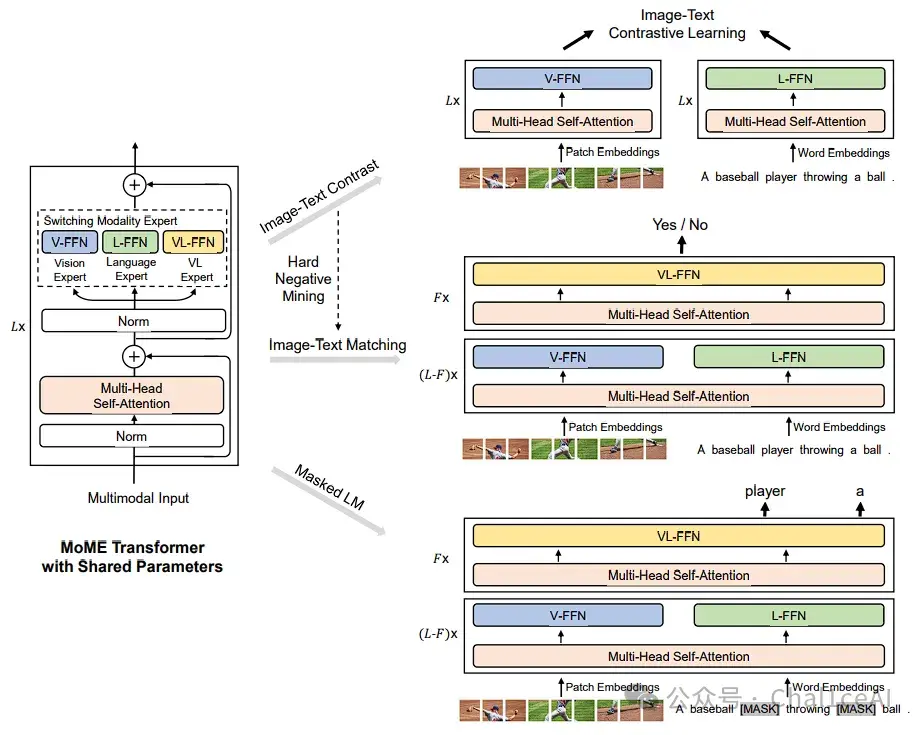
自注意力那部分是共享的,不管是单独编码图像、单独编码文本还是图文一起编码,都用同一套自注意力,专家组里切到不同专家来干活,就能既抓住单模态特征,也能做深度跨模态交互。
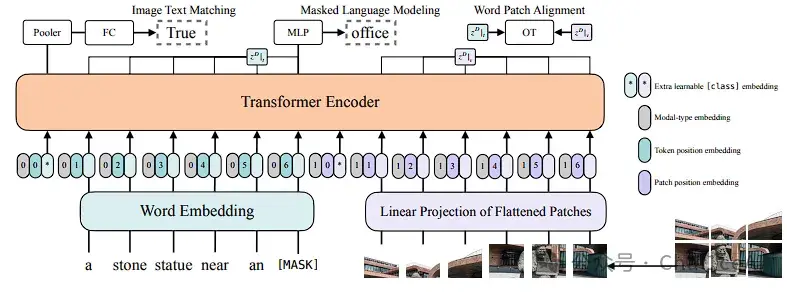
细节上,VLMo是先把图片切 patch、flatten、然后linear投影到embedding 空间,文本用BERT‑style做 wordpiece 和位置/类型嵌入

接着把[I_CLS]、图片patch embeddings、[T_CLS]、文本token embeddings 串在一起,输入到MoME Transformer。Transformer里每层有:共享 self‑attention + 不同专家池(Vision-FFN、Language-FFN、Vision-Language‑FFN)供路由器(gating)选用,从而支持三种模式:图像独立编码、文本独立编码和图文一起编码。
再说预训练套路,VLMo 还弄了个分阶段(stagewise)预训练。先在大规模无标注图像上做类似 BEiT 那样的遮 Mask 图像建模,只训练Vision-FFN和自注意力
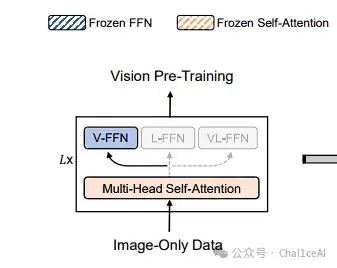
接着把这些图像专家和自注意力冻住,在海量文本上跑MLM,训练Language-FFN
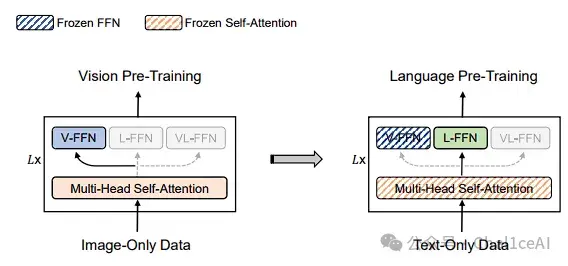
最后把整套模型加载到图文预训练(包括图文对比、图文匹配、Masked LM)上跑一遍,充分利用单模态和多模态数据。
这么干的好处是弥补了纯图文对数据集规模小、文本短的问题,让模型先学到通用的视觉和语言表达,再做跨模态对齐。
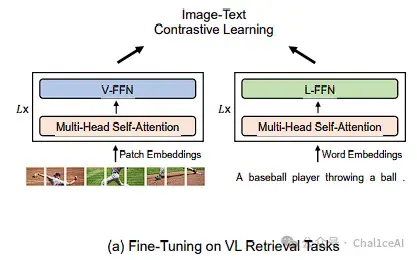
有了这两个核心——MoME Transformer + Stagewise Pre‑training,VLMo 在下游就能“凭“模式””来用:检索的时候当双编码器,用image-text contrastive loss,检索速度和 CLIP 差不多;
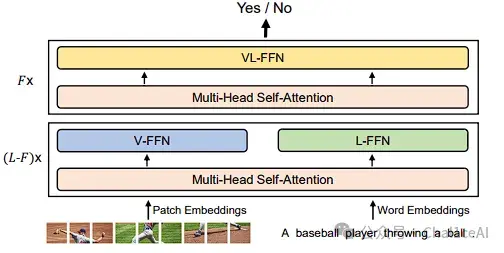
做VQA、NLVR2这类分类任务时当融合编码器,把[T_CLS]最后的输出接全连接层,就能做判别。
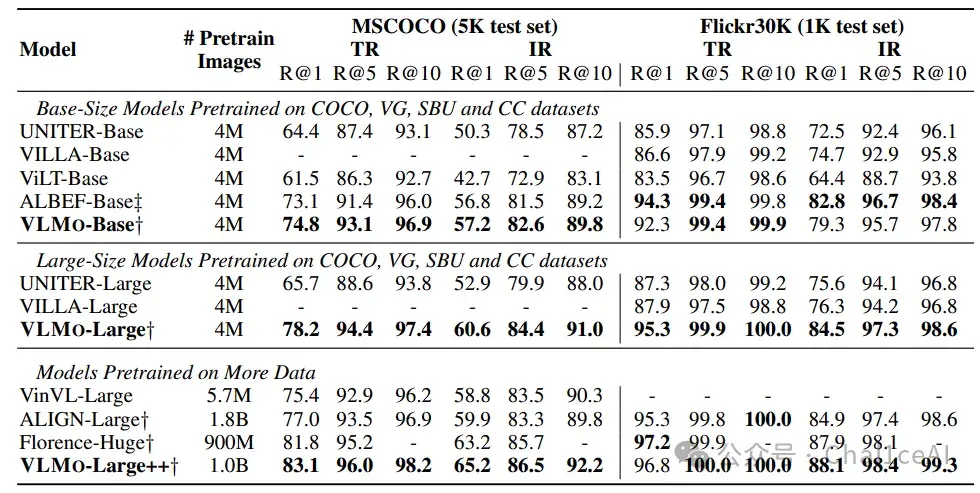
性能上也非常给力。Base‑size 的VLMo‑Base在COCO text-to-image R@1 跑到了74.8%,高过ViLT‑Base(61.5%)和ALBEF‑Base(73.1%);Large‑size的VLMo‑Large R@1能到 78.2%,甚至自己scale到十亿对噪声图文时(VLMo‑Large++),COCO R@1达到83.1%,Flickr30k R@1有 65.2%。
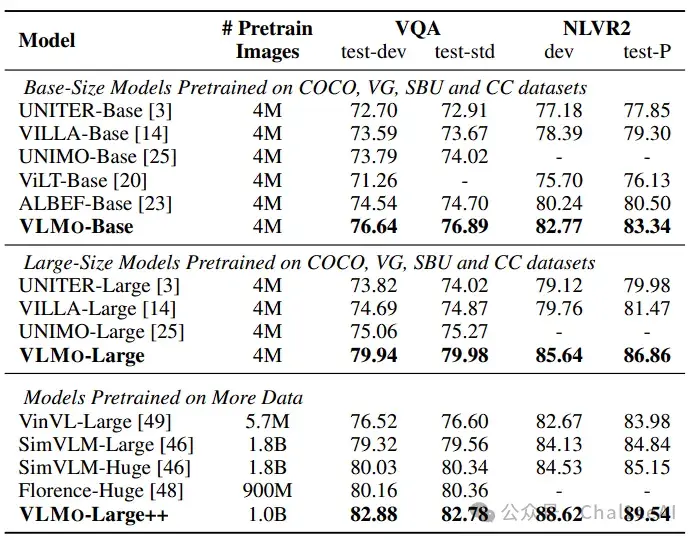
分类任务上,大模型VLMo‑Large++在VQA test‑dev拿到 82.88 分,在 NLVR2 public test上是88.62分,超越了当时很多基于区域特征的大体量模型。
总的来说,VLMo的贡献在于:把Moe的思想代入了多模态,用一个统一的MoME Transformer结构,既能做双编码检索又能做融合分类,并且通过分阶段预训练充分利用单模态和多模态数据,达到了效果和速度都不打折的兼顾。下次做图文任务,再也不用纠结到底选哪种架构了。
参考资料: