ViLT论文详解,来看看这篇论文有什么创新点
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
这篇论文全称是《ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision》,当然,重点在于它提到的Without Convolution or Region Supervision。也就是说没有目标检测器或者卷积处理架构的模型。
论文链接:
https://arxiv.org/pdf/2102.03334
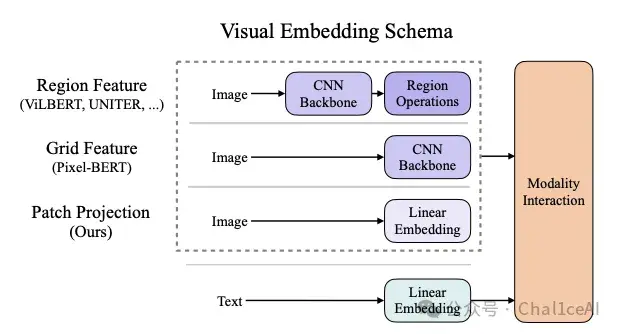
作者从一开始就把之前多模态研究的常用的流程给放到这个图里面,在视觉方面,以往大多数的研究都会用卷积层来提取图片的这个特征,然后去做成bounding box的方式,去做一个目标检测之类的任务,也就是图中的Region Feature这一部分。
或者不要目标检测器,直接把图像抽取图片的特征,利用CNN把最后一层特征层拎出来,拉直后丢给后面处理,这是图片当中的Grid Feature部分。
而文本方面都是直接通过一个Linear embedding模块去把每个词做成word embedding的形式,然后再和视觉方面的序列丢给后面的模态融合模块处理。
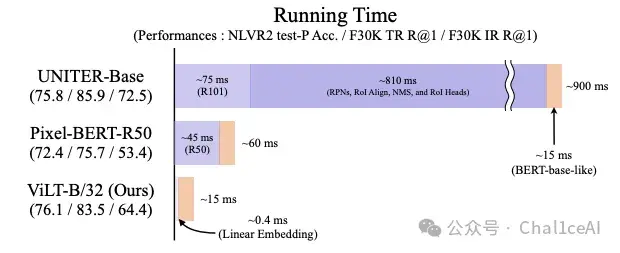
而在以往的研究里面,因为用到了区域特征处理,也就是目标检测器这一类的东西,所以会导致处理时间特别的长,这点可以看图片中的UNITER-Base部分,浅紫色是卷积提取图片特征消耗的时间,深紫色是区域特征处理的时间,暗黄色是文本处理的时间。
对应的,把目标检测这一个任务去掉之后,只剩下卷积特征提取,能够把时间压缩到45ms左右。
作者针对这种情况,就把特征提取模块替换成linear embedding模块,图像展开成patch向量之后,经过这个模块变成patch embedding,本质上这就是一个矩阵乘法。
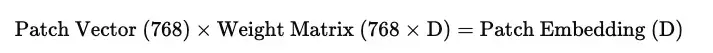
一般来讲,流程应该是这样:图片 → patch划分 → flatten → linear embedding → patch序列,ViT、MAE之类的结构,都是这个套路,作者也是参考了ViT的思想。
下面这张图是ViLT的整体架构示意,基本可以分为三大部分:输入表示(左下),Transformer 编码器(中部),和三种预训练任务头(顶部)。
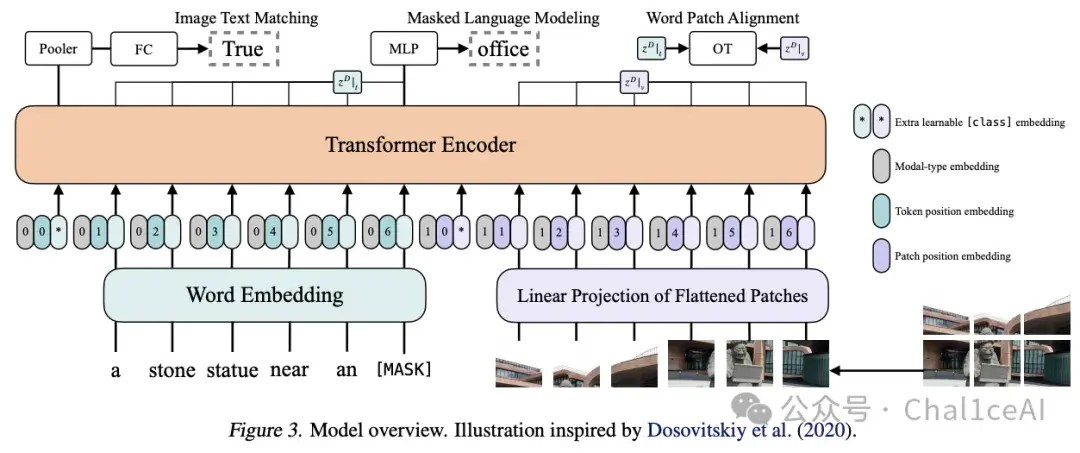
我按从下到上的流程把各个部分拆解一下:
- 输入表示(Embedding)
图底部我们看到两条并行的输入流,左边是文本输入,右边是视觉图片的输入:
1.文本流(左边)是先把一句话(例如 “a stone statue near an [MASK]”)拆成token,用 BERT-style 的词嵌入把每个token编成向量,图片里面的浅蓝色部分就是它的每个文本token的一个位置信息(0, 1, 2…)。 2.视觉流(右边)把图片切成若干个固定大小的非重叠patch,然后拉成向量,经过linear embedding层把每个 patch 映射到同样维度的embedding空间,形成一串“视觉 token”。 3.[class] Token 在最前面额外加一个可学习的[CLS](图示上带*),用它来做全局汇聚(pooling),给后续做图文匹配任务。 把这三部分的 embedding(Word/Linear + Position + Modal +[CLS])相加,然后串联成一个长序列,形式上就是这样:
[CLS] a stone statue … [SEP] patch₁ patch₂ … patchₘ
- Transformer 编码器
将上面得到的混合序列(文本 tokens + 图像 patches +[CLS])一起送进一个标准的Transformer Encoder,文本和视觉信息在每一层都能相互attend,做深度的跨模态交互,不像有些早期模型要先各自跑完各自的backbone 再对齐。
- 三大预训练任务头
中间的这个transformer模块把序列编码完处理完之后,会接三个不同的任务头来共同训练,从左到右依次是ITM,MLM和WPA。
ITM从简单来讲就是做一个图像文本对匹配的任务,用 [CLS] 位置的输出,接一个全连接(FC)+ Pooler,判别当前图文对是不是True(匹配)还是False(不匹配),其实也就是一个分类的任务。
MLM是我们nlp领域平时做的最多的,这里是对随机把部分文本的token给mask遮掩掉(图里示例把 “office” mask 掉),用对应位置的Transformer输出去预测原词,也就是所谓的完形填空任务。
不过这里要注意一点的是,作者是把整个词给遮掩掉,而不是把遮掩掉其中的部分token,作者说了让模型猜中间的字母会导致训练出来的模型在图文上面的性能不行,模型只记得单词怎么拼,不会去了解图片和文本之间的联系。

最后那个是WPA,也叫OT对齐,其实就是计算图片和文本之间的距离,对应论文里的optimal transport任务,让部分文本token(如 “office”)和图中正确的 patch 向量分布对齐,鼓励模型学习更精细的跨模态对齐。
三者同时训练,可以让模型学到整体的图文匹配,又掌握语言填空,还能学到局部的词—图像区域对齐。
作者这篇论文的贡献不是说ViLT的性能比起之前有多棒,而是把视觉部分的处理时间给压缩到很快的地步,而且用上了图片增强,效果显著,之前的多模态研究是没有用上这个处理的,
作者在论文里是用到了RandAugment,除了改变颜色和裁切图片没有用,其他是尽量的用上了,因为做图文任务的时候,如果图片颜色改变了或者把图片的某一部分裁切下来之后,可能会导致文本的描述和图片不一致。

作者在论文里面的一张图也提到一些其他信息。
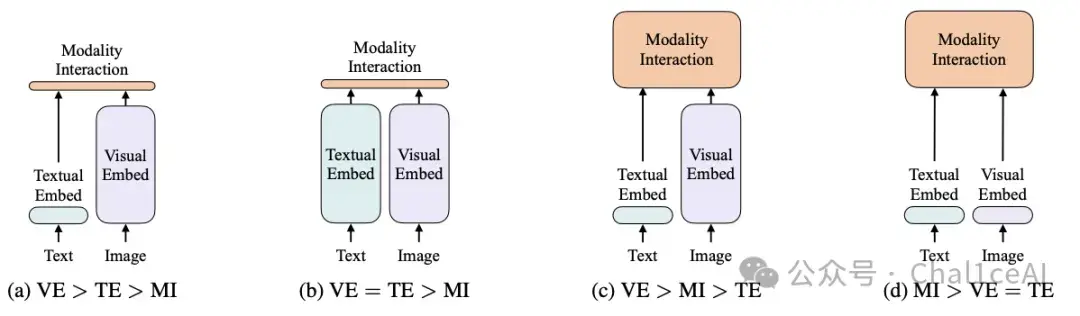
作者要表达的应该是如果要多模态做得好,那后面模块融合这一个阶段才是比较重要的,前面的特征提取反而不是那么重要。
最后的那些数据集之类的,还有其他的一些细节,大家可以自行去论文当中去翻一下。